推荐系统概要
info
01 小红书的推荐系统
1.1 信息流推荐路径
- 发现页: 推荐内容的主入口
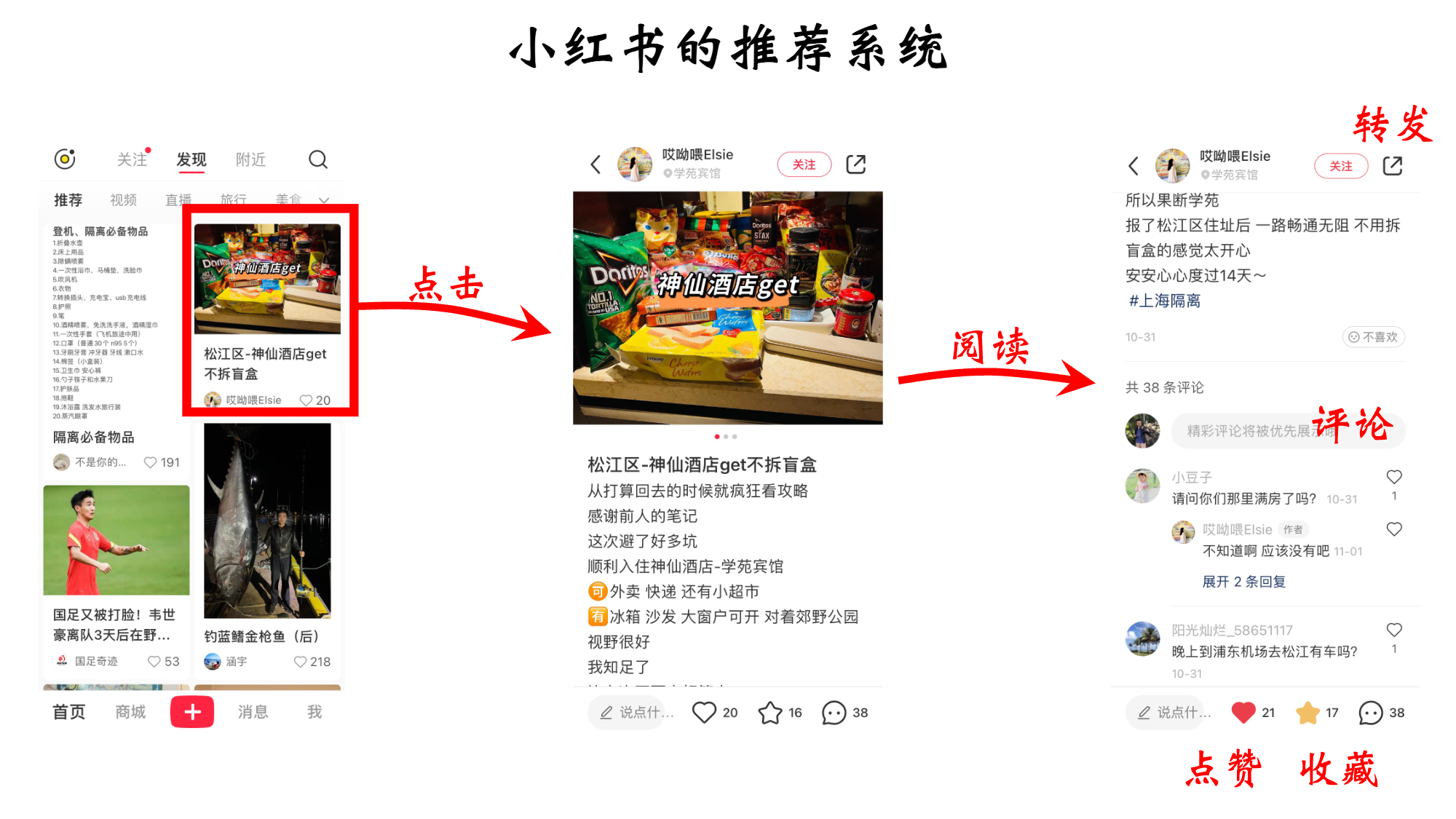

1.2 用户行为反馈和消费指标
- 消费指标: 反映用户对推荐是否满意
- 点击率 = 点击次数 / 曝光次数 —— 越高,证明推荐越精准 —— 不能仅追求它,不然都是标题党了
- 点赞率 = 点赞次数 / 点击次数
- 收藏率 = 收藏次数 / 点击次数
- 转发率 = 转发次数 / 点击次数
- 阅读完成率 = 滑动到底次数 / 点击次数 × (笔记长度) —— 用于归一化
- 这些都是短期消费指标,不能一味追求
- 因为重复推荐相似内容可以提高消费指标,但容易让用户腻歪,进而降低用户�活跃度
- 而尝试提供多样性的内容,可以让用户发现自己新的兴趣点,提高活跃度(但在这个过程中,消费指标可能下降)
反正就是尽量让用户多在平台投入精力
- 北极星指标 —— 衡量推荐系统好坏 —— 在小红书考虑下面 3 个
- 用户规模
- 日活用户数(DAU)、月活用户数(MAU)
- DAU:每天使用 1 次以上
- MAU:每月使用 1 次以上
- 消费
- 人均使用推荐的时长、人均阅读笔记的数量
- 发布
- 发布渗透率、人均发布量
- 用户规模
- 北极星指标 都是线上指标,只能上线了才能获得
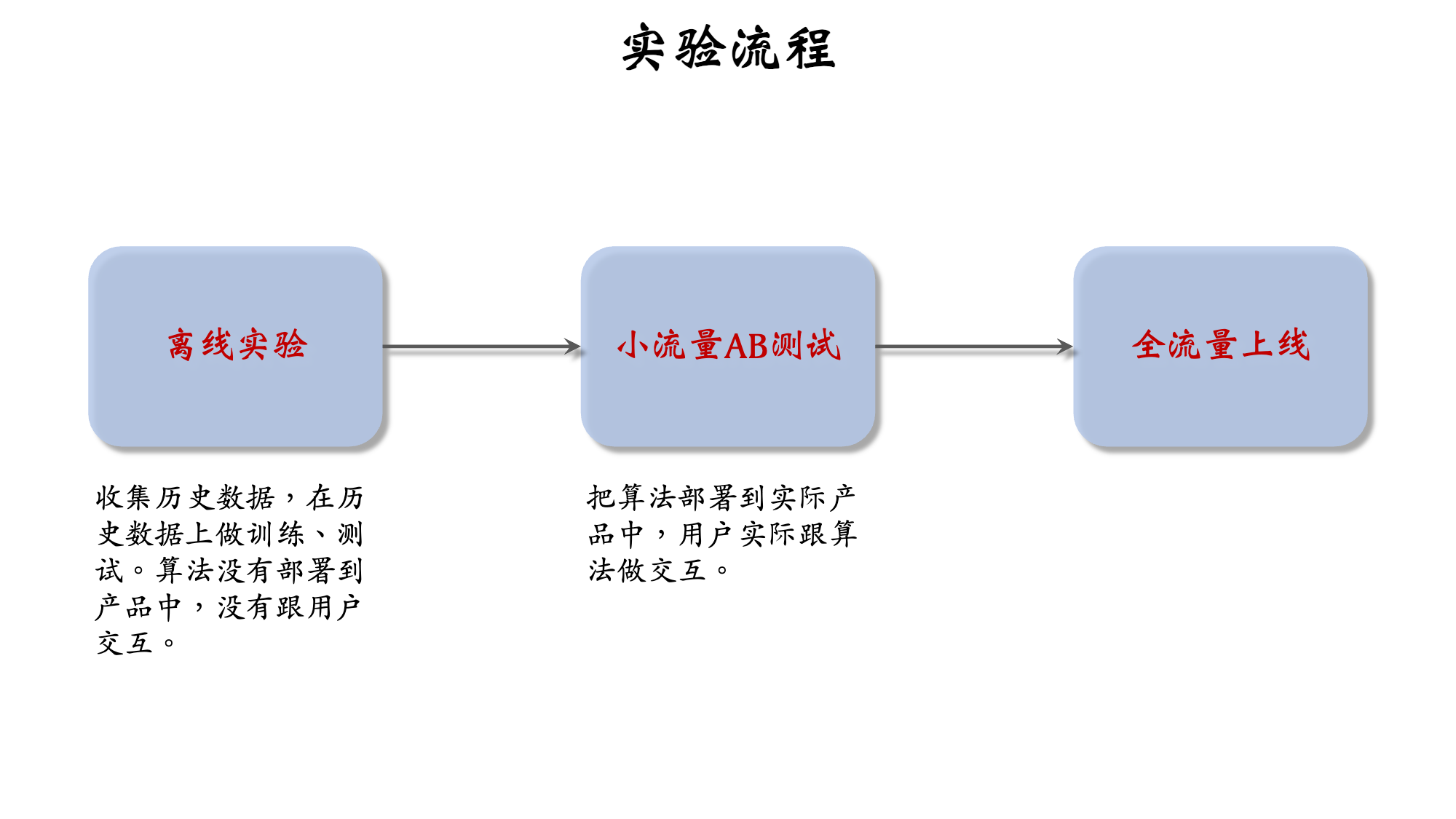
1.3 算法迭代流程 - 从离线实验到全量上线
02 推荐系统的链路
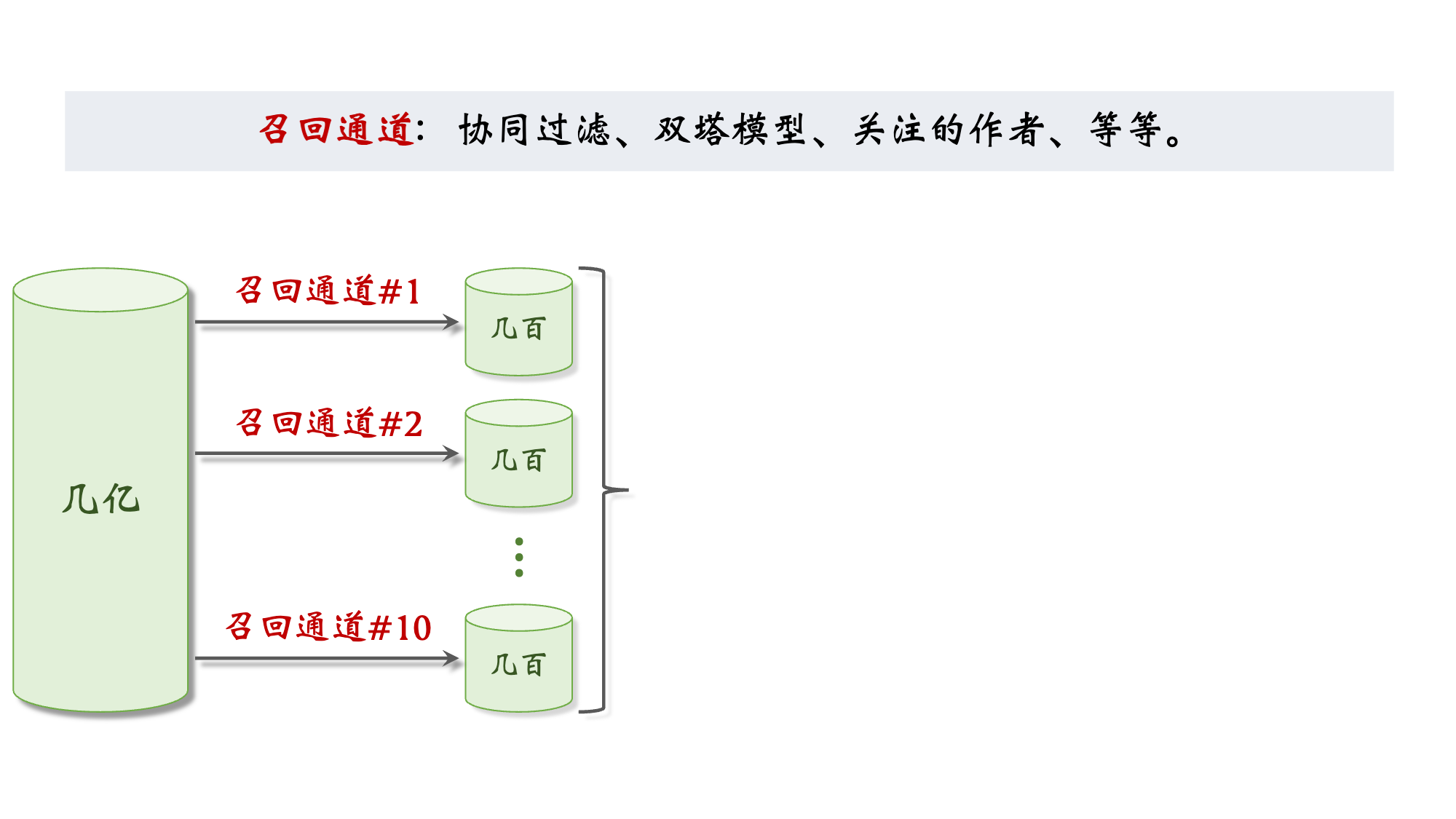
2.1 召回 Retrieval
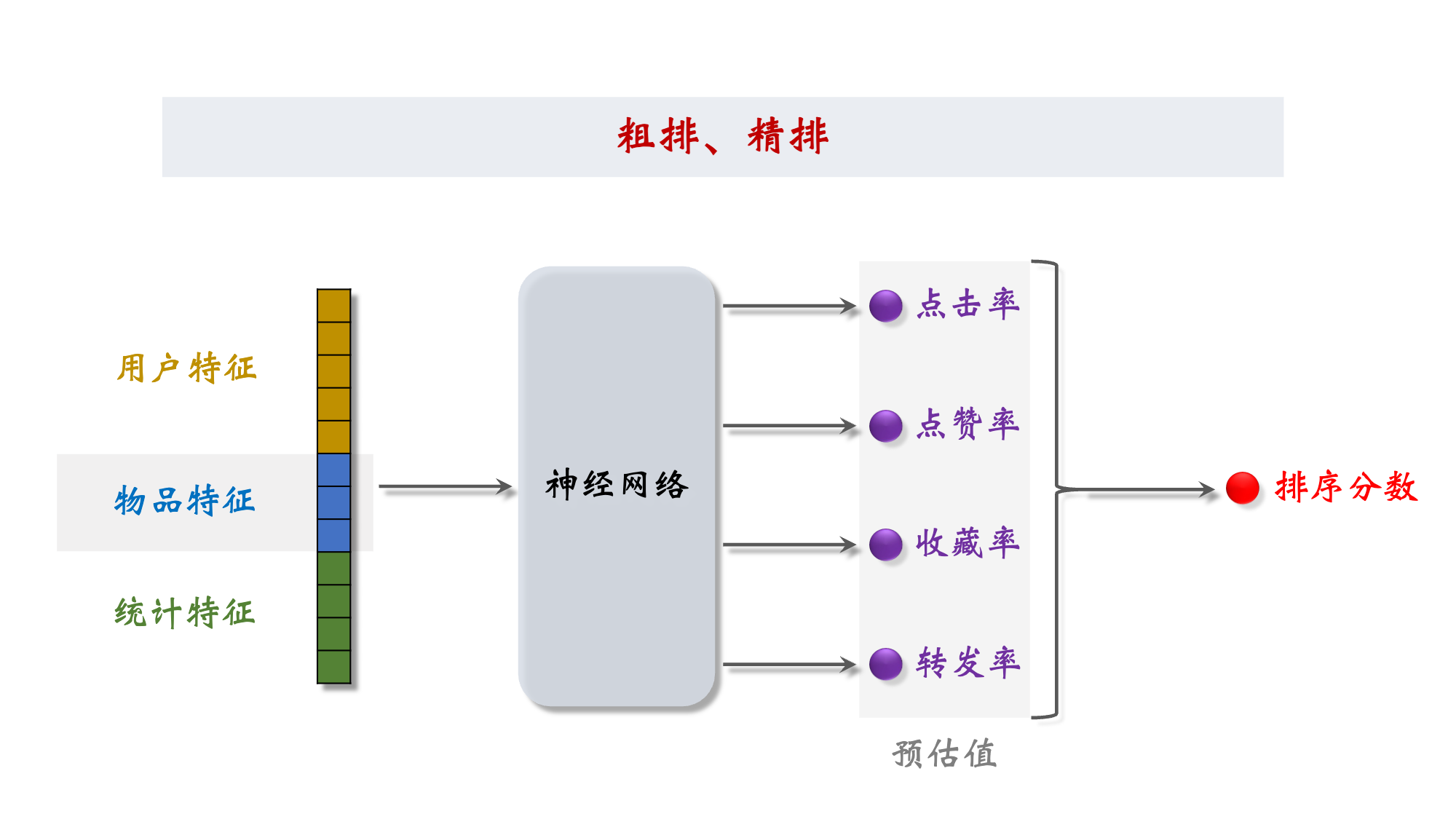
2.2 排序 Rank
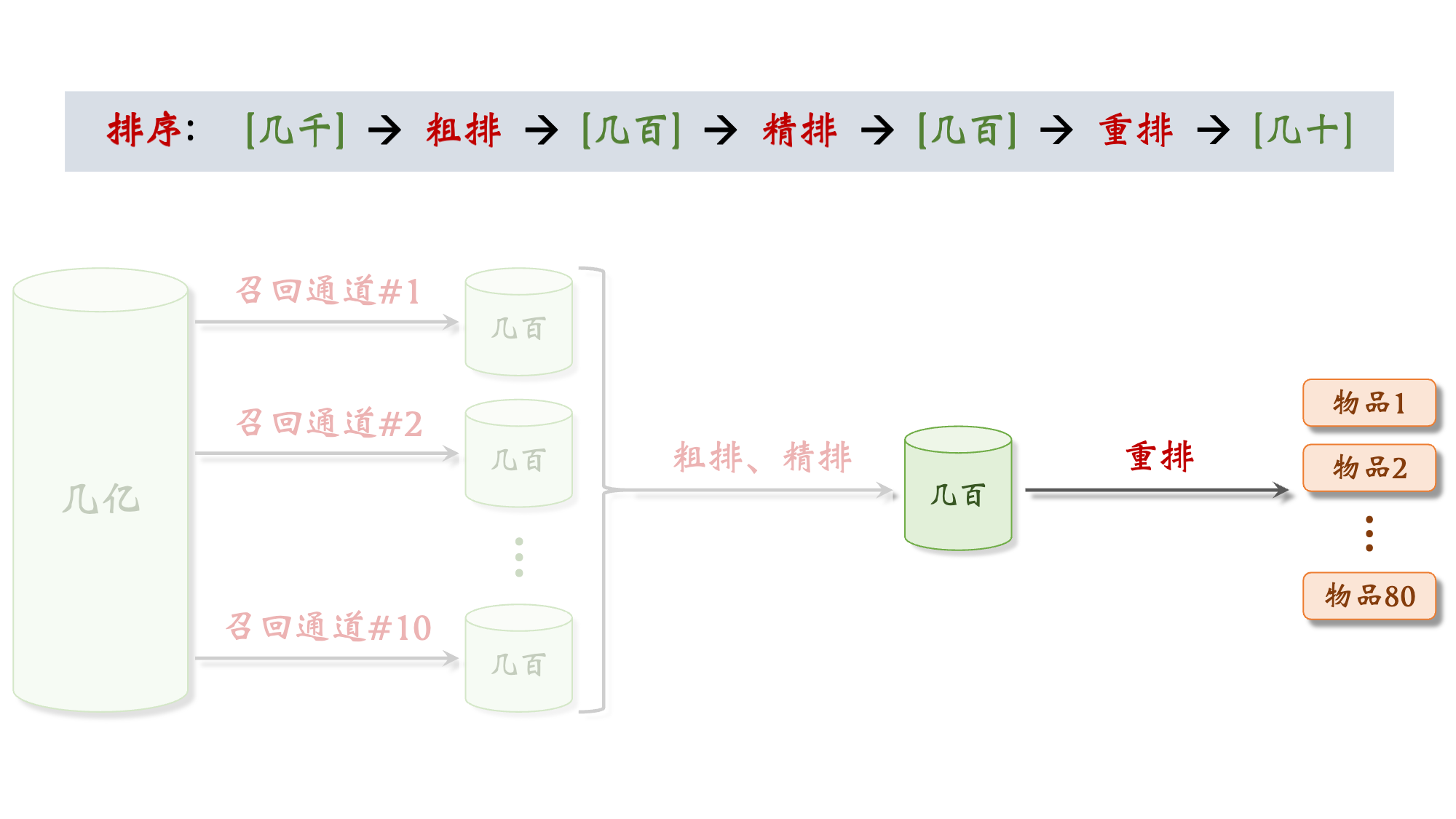
2.3 粗排精排 Cascade & Rank
2.4 重排 Re-Rank
Re-Rank阶段是推荐系统的最后一公里,既是体验优化器,也是利益调控器。需在“个性化 + 多样性 + 生态 + 商业”多目标间平衡,核心不在于模型,而在于策略工程 + 策略融合。
多样性抽样 (Diversity Sampling)
- 目的: 避免相似内容“刷屏”,提升信息多样性与探索性。
- 方法:
- MMR (Maximal Marginal Relevance):在兼顾相关性与多样性的基础上迭代抽取
- 典型目标函数为
score(d) = λ · Rel(d) − (1 − λ) · max_{d' ∈ S} Sim(d, d') - DPP (Determinantal Point Process):基于子集选择的概率建模,倾向于选择低相关、高覆盖度的内容子集。
- 实际表现: 在个性化推荐中提升内容广度,降低跳出率与审美疲劳。
规则打散 (De-Duplication & Scattering)
- 目的: 防止高度相似笔记连发导致用户感知“刷屏”,打断信息流。
- 策略
- 控制同一用户/商品/话题笔记在结果中的最大展示间隔;
- 设置内容打散阈值:如编辑距离、embedding 相似度等;
- 对同质内容进行 group-based 排序打散 (group-aware rank shuffle);
- 效果: 提升信息丰富性,增强“刷内容”的节奏感与可读性。
插入广告/运营内容 (Mixed Content Insertion)
- 目的: 在主Feed中穿插平台商业内容或运营推广,兼顾体验与变现。
- 类型:
- 广告 Ads: 精准定向投放,通常基于CTR预估后穿插指定位置
- 运营卡片: 平台推荐内容,如活动推广、新品曝光等
- 插入机制:
- 固定槽位 (如第5条、第10条插广告)
- 动态插入 (根据用户耐受度动态控制ad density)
- 排序控制:
- 广告/运营内容的插入权重由收益预估 + 生态调控因子共同决定
- 要求内容质量不低于自然内容,以防影响整体点击体验。
生态排序调整 (Ecological Constraints)
- 目的: 平台需兼顾内容生态健康、防止单一创作者/品类过度曝光。
- 策略:
- 内容多元保护:限制爆款笔记/头部创作者内容霸屏;
- 平衡新老内容、新老作者、新老商品的展现机会;
- 控制敏感内容、过度营销内容、低质内容的排序曝光。
03 A/B 测试流程
3.1 为什么需要A/B测试?
- 召回团队实现了一种 GNN 召回通道,离线实验结果正向
- 下一步是做线上的小流量 A/B 测试,考察新的召回通道对线上指标的影响
- 模型中有一些参数,比如 GNN 的深度取值 ,需要用 A/B 测试选取最优参数
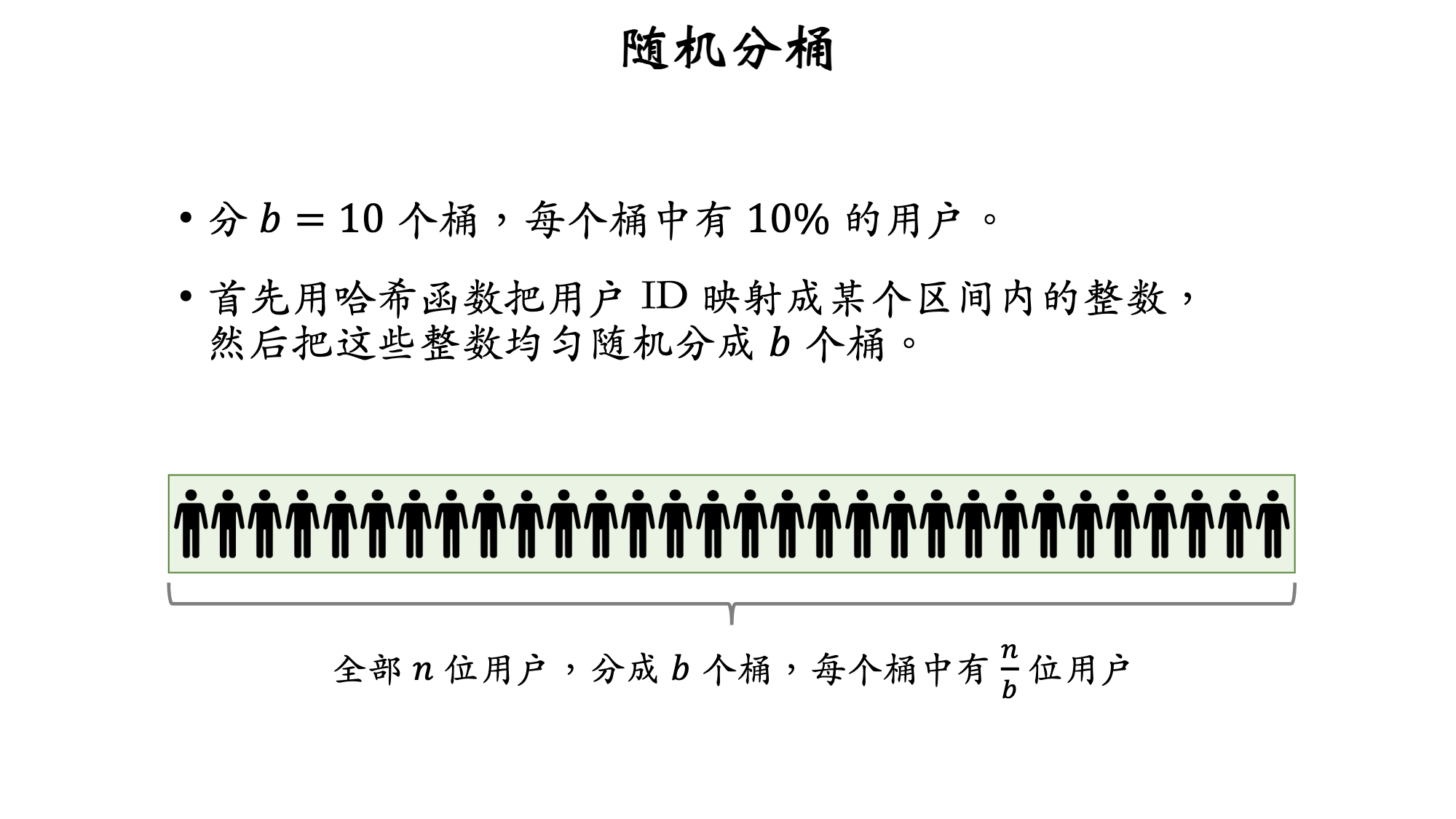
3.2 分桶实验
- 分
b = 10个桶,每个桶中有 10% 的用户 - 首先用哈希函数把用户 ID 映射成某个区间内的整数,然后把这些整数均匀随机分成 b 个桶

3.3 分层实验
流量不够用怎么办?
- 信息流产品的公司有很多部门和团队,大家都需要做 A/B 测试
- 推荐系统(召回、粗排、精排、重排)
- 用户界面
- 广告
- 如果把用户随机分成 10 组,1 组做对照,9 组做实验,那么只能同时做 9 组实验


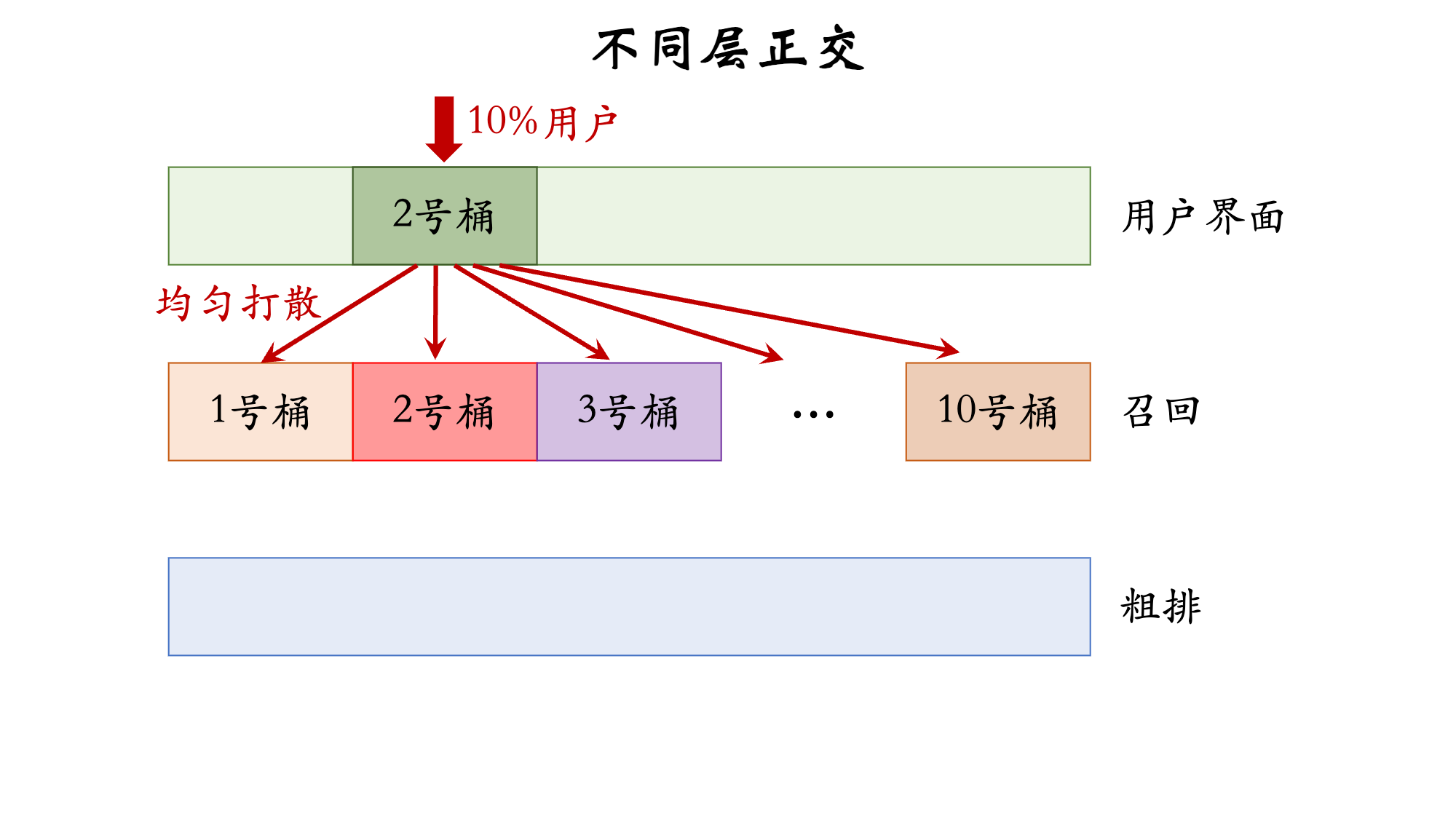
3.4 互斥与正交
- 如果所有实验都正交,则可以同时做无数组实验
- 必须使用互斥的原因
- 同类的策略(例如精排模型的两种结构)天然互斥,对于一个用户,只能用其中一种
- 同类的策略(例如添加两条召回通道)效果会相互增强(
1+1>2)或相互抵消(1+1<2)。互斥可以避免同类策略相互干扰
- 不同类型的策略(例如添加召回通道、优化粗排模型)通常不会相互干扰(
1+1=2),可以作为正交的两层

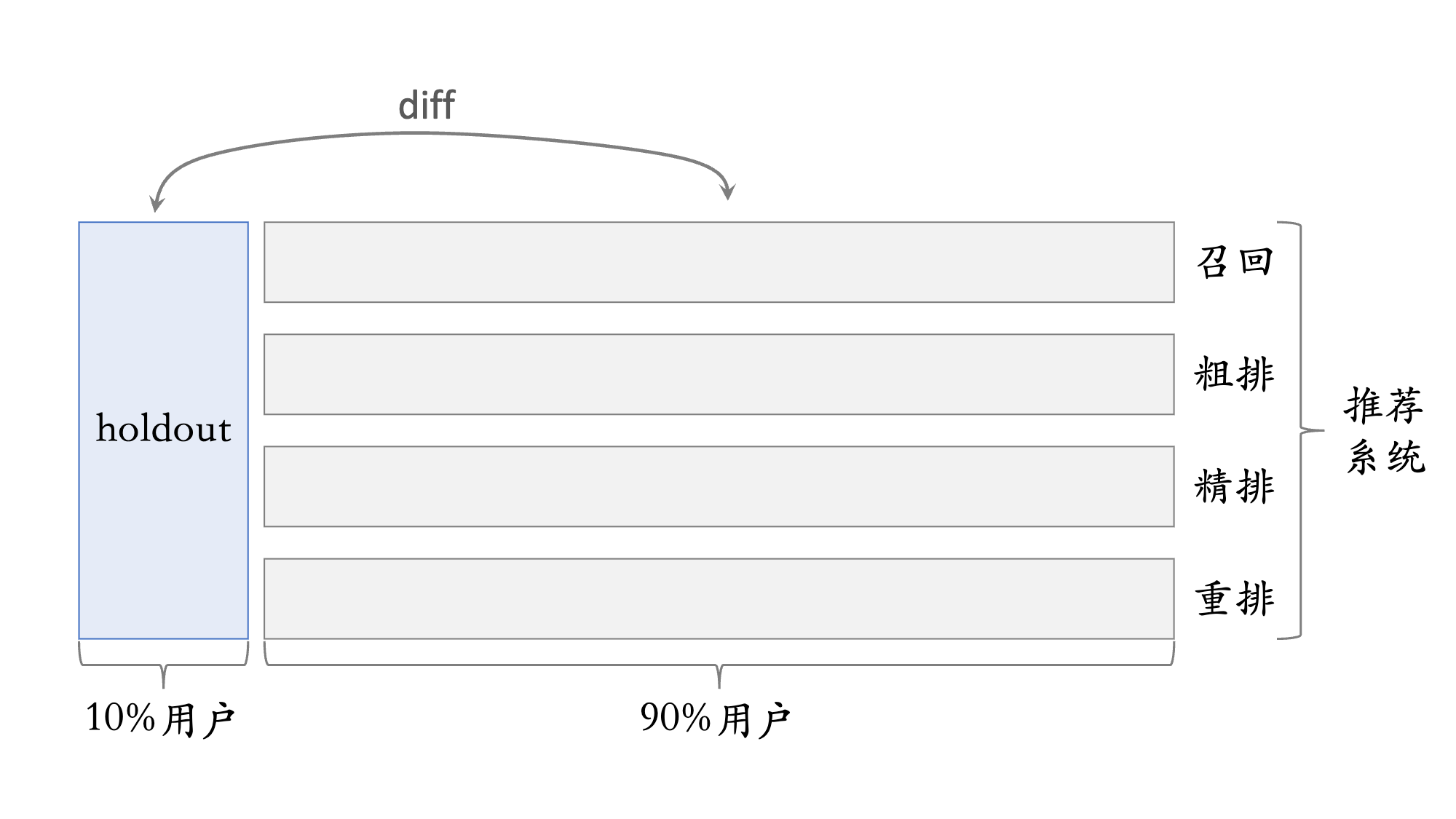
3.5 Holdout 机制
- 每个实验(召回、粗排、精排、重排)�独立汇报对业务指标的提升
- 公司考察一个部门(比如推荐系统)在一段时间内对业务指标总体的提升
- 取 10% 的用户作为 holdout 桶,推荐系统使用剩余 90% 的用户做实验,两者互斥
- 10% holdout 桶 vs 90% 实验桶的 diff(需要归一化)为整个部门的业务指标收益

holdout 桶里面不加任何新的实验,保持干净以便对照
- 每个考核周期结束之后,清除 holdout 桶,让推全实验从 90% 用户扩大到 100% 用户
- 重新随机划分用户,得到 holdout 桶和实验桶,开始下一轮考核周期
- 新的 holdout 桶与实验桶各种业务指标的 diff 接近 0
- 随着召回、粗排、精排、重排实验上线和推全,diff 会逐渐扩大
3.6 实验推全 & 反转实验
当前有一个重排实验,在 90% 实验桶中的 20% 用户上进行
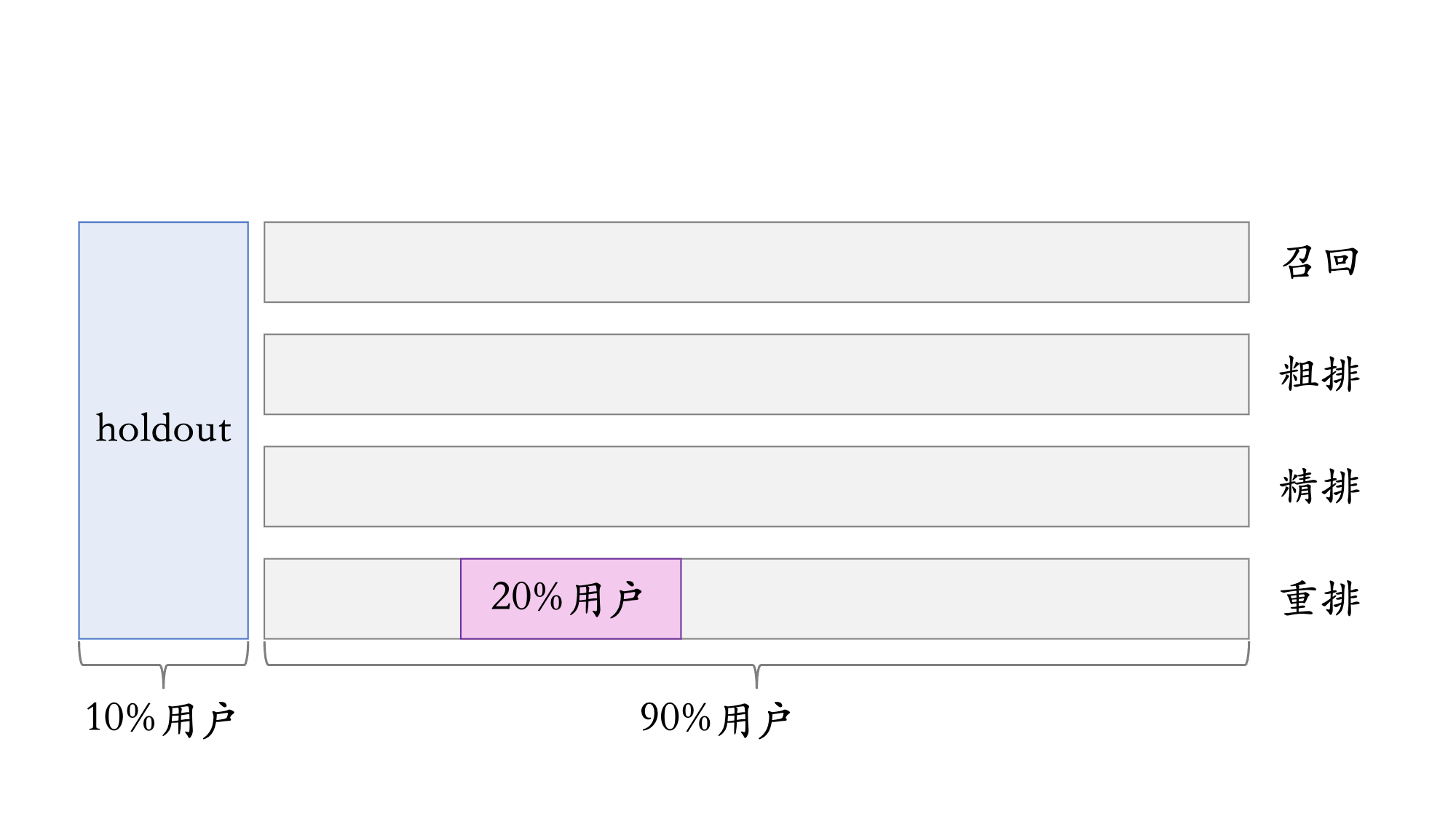

- 有的指标 (点击、交互) 立刻受到新策略影响,有的指标 (留存) 有滞后�性,需要长期观测
- 实验观测到显著收益后尽快推全新策略。目的是腾出桶供其他实验使用,或需要基于新策略做后续的开发
- 用反转实验解决上述矛盾,既可以尽快推全,也可以长期观测实验指标
- 在推全的新层中开一个旧策略的桶,长期观测实验指标
